However, in the end, we still had many questions that couldn't be answered:
- What is the encryption routine used for thr1.chm and mmc109.exe?
- Why does the malware rename mmc109.exe to mmc61753109.exe?
- Why does the malware first make a network connection to Adobe.com? What does that POST value mean?
- Why does the initial loader contain so few strings?
These questions are best answered through static analysis. However, static analysis can be an extremely time-consuming activity. A full "deep dive" static analysis could take days, or even weeks, to fully document all functionality within a malware sample. Instead, this post will go through the process of a targeted static analysis. With the questions laid out here, we'll focus our static analysis solely on answering those questions, which will mean leaving many aspects of the malware undocumented.
Therefore, we need to focus on what questions can be answered within an hour or two of static analysis.
These questions mirror some of those performing Incident Response work. During incident response work a malware analyst works in conjunction with forensics and the responders to help answer the really difficult questions on why certain indicators are seen, what they mean, and what other indicators should be searched for that may have been missed.
This also answers the concerns of inaccurate preconceptions from those outside the field. When I tell a client that a sample has encoded data and will take a bit longer, I immediately get push back on the expectation that a simple routine may add 40+ hours of billable time. Likewise, if I say that a sample has a custom encryption routine, I'd often get pinged every hour on why it's not decoded yet.
This post will show some of my personal workflow and mentality when trying to analyze malware, while trying to extract indicators to assist in an overall forensics examination or incident response. As I'm new to much in the RE world, having only learned through self-training and on-the-job work, I'd love any feedback for ways in which to speed up or better hone topics that I covered here.
Therefore, we need to focus on what questions can be answered within an hour or two of static analysis.
These questions mirror some of those performing Incident Response work. During incident response work a malware analyst works in conjunction with forensics and the responders to help answer the really difficult questions on why certain indicators are seen, what they mean, and what other indicators should be searched for that may have been missed.
This post will show some of my personal workflow and mentality when trying to analyze malware, while trying to extract indicators to assist in an overall forensics examination or incident response. As I'm new to much in the RE world, having only learned through self-training and on-the-job work, I'd love any feedback for ways in which to speed up or better hone topics that I covered here.
First off, we'll be using IDA Pro in this post. IDA is a commercial tool that is used for in-depth static analysis. There is a free version of IDA available for download, though very outdated. The newest versions of IDA also have an optional decompiler, at an additional cost. For general use, however, the pay-to-play cost is out of reach of many reversing hobbyists.
Alternatively, there's Hopper - a commercial, but very inexpensive, static analysis tool. Hopper has a decompiler built in, but its feature set (and decompiler ability) lags greatly behind IDA.
For our purposes here, both are usable. I use IDA Pro at work and have a license for home, though the home one is limited to an older version. I also have a personal Hopper license to play with as needed.
For simple static analysis, Hopper is all you need, as shown in the chart below. As the complexity of the samples increase, you may need to move to IDA Pro for its functionality (or use Hopper and take really good notes). To compare the differences, note the graphic below showing IDA Pro on the left, Hopper Decompiler on the right:
For simple static analysis, Hopper is all you need, as shown in the chart below. As the complexity of the samples increase, you may need to move to IDA Pro for its functionality (or use Hopper and take really good notes). To compare the differences, note the graphic below showing IDA Pro on the left, Hopper Decompiler on the right:

Now, let's get started with this sample from the earlier post. For the sake of this post, I will stick to the IDA Pro.
Loader Analysis
In Part 1 of this post, we performed dynamic analysis on the sample and ultimately determined that the initial file was a memory loader for the actual Trojan. This creates the issue of two separate files that require analysis. We'll separate our analysis between the loader (here) and the trojan (farther down).Before performing in-depth analysis, we need to do basic normalization of the file. This includes decoding any encoded strings, resolving any API calls, and generally getting all of the small hurdles out the way.
Encoded Windows API
Earlier string analysis showed a distinct lack of API calls. So, one of our first steps is to learn for any traces of API resolution, typically in the form of API name "strings" being passed to GetProcAddress().Looking at the initial start() routine, there are a few things that pop out. There's liberal use of global DWORD variables, seen as "dword_<address>". This is also one of Hopper's weak points, as changing a global variable name in one routine does not cross over to others, IDA is better equipped to handle malware like this.

These global DWORDs are seen being used to store values and, at near the bottom, as APIs. (call dword_40CAF0). From this we know there is some dynamic API resolution occurring within the code, but we still have a lack of strings from which APIs could be resolved from. If there is dynamic API resolution, it will occur very early in the runtime. So, let's start down the subroutines chronologically.
One of the first calls is to push a block of raw data (unk_40C8DC). This data appears as:

From the start of the data, down to the nulls at the end, this appears lightly encoded.
Before handling that data, the code calls GetModuleHandleA("kernel32.dll") and places the result into dword_40CAAC. Name the DWORD with a description (kernel32_handle) and proceed. Now we see the unknown block of data being passed into sub_4012E0.
If we follow this data onward, we see it passed into sub_401200. The portion of this subroutine that decodes the block of data is shown below:

This routine steps through the data until the position (ebp+var_4) is at 234 bytes, a number which coincidentally is the exact size of the data block. For each iteration, four bytes of data are extracted. The DWORD integer value of those four bytes is subtracted by the position offset. The value is then subtracted again by the hex value 0x85BA. Being a Python person, I duplicated the process with:
import struct data = open('api_data', 'rb').read() result = '' for pos in range(0, 232, 4): temp = struct.unpack('l', data[pos:pos+4])[0] temp -= pos temp -= 0x85BA result += struct.pack('l', temp) print result
Upon execution, this data decoded to a set of null-terminated strings:
ìetWindowsDirectoryA VirtualAlloc VirtualFree CreateFileA HeapAlloc GetProcessHeap VirtualProtect MapViewOfFileEx LoadLibraryA UnmapViewOfFile CreateFileMappingA CloseHandle GetProcAddress lstrcatA FindAtomA AddAtomA GetModuleHandle
We've found our API calls! The first one is off, likely due to the malware keeping the first byte back for inclusion later on. But, wait, there's more. In the IDA graph above there's a second set of instructions on the right side for '3etProcAddr'. Knowing our APIs, that should be GetProcAddress. A look at this code shows that it's basically doing a memcpy() of '3etProcAddr' into 0x40CB20. Immediately afterward are direct byte placements into specific offsets. Byte 0x40CB20 becomes 'G', which replaces the '3'. 0x40CB2B, 0x40CB2C, 0x40CB2D, and 0x40CB2E are all set to "ess\00" respectively. Knowing this, I rename &byte_40CB20 to a description 's_GetProcAddress' (s_ denoting a string).
Immediately afterward we see the earlier named kernel32_handle passed into sub_401130. Delving in here, I see the presence of 's_GetProcAddress' from just above. Without going into more analysis, I can make a very good guess that this routine just resolves the API of GetProcAddress and returns it. Sure enough, in our decoding routine, I see the result placed into the global dword_40CAF0, which I now rename to 'api_GetProcAddress'.
If I follow the references (XRefs) to api_GetProcAddress, I see a usage in a subroutine we haven't looked at yet, sub_401DF0. Going there is a very simple routine the decompiles to simply:

Ding! With that known, we can rename sub_401DF0() to ResolveAPI(), and see how it's used. (Astute analysts will realize there's something wrong here... we'll come back to that later)
API Assignments
When I work my way back to where this block of APIs is being used, I see this block of code that is best represented in decompiler view:

This is just a small segment of the overall routine, but it shows the parsed API strings being resolved. Their resolved API hashes (stored as a DWORD) are then placed into a sequential series of DWORDs starting at 0x40CAC0 (which I've named API_List). A separate global DWORD (named API_Counter) is used as an incremental counter to apply each string to its DWORD value.
When I view that list of DWORDs, started at 0x40CAC0, I see a series of sequential global DWORDs just waiting to contain APIs:

Our first inclination would be to just go down the line and rename them all based upon our text API strings. This would be wrong :) Why? Because take a careful look at the offsets, particularly those with an 'align 10h' by them. There are no DWORDs associated with these locations; the APIs are being resolved during runtime but IDA is showing us that they are never actually in use. We can confirm the offsets and locations by viewing the results in a debugger.

So, by counting carefully, we can scratch off CreateFileA, lstrcatA, FindAtomA, and AddAtomA. When done, the list should look like this:

Some people may notice a small error in this setup. When resolving APIs, the malware tried to resolve the API of "ìetWindowsDirectoryA", which is obviously not valid. The first DWORD should be for GetWindowsDirectoryA(), but because of the corrupted first byte, it didn't resolve and appeared as four nulls in the debugger output above. Had it worked, my DWORD of API_List should have been GetWindowsDirectoryA.
Now, when we go back and look through the code, functionality will be much clearer.
IDA Pro Decompiler Errors
One of the hardest lessons to learn with IDA Pro is to never trust the decompiler. For really quick static analysis, it's a life saver. You can breeze through malware samples, quickly determining the overall functionality with ease. But, when it comes to the small intricacies there are usually errors in its output.
This is apparent in this sample. In the earlier routine, where the resolved API calls are placed into a series of global DWORDs, the decompiled output appeared as:

However, at a glance, this doesn't make any sense. Why would a variable container hold the results of the same call over and over? How would a function that resolves an API take only the handle to kernel32.dll?
The problem exists within the function named ResolveAPI():

However, when this function is decompiled, it appears as:


There's a massive difference in functionality. For one, the return block (disassembly view bottom right) references two function parameters (arg_0 and arg_4). But, the decompiler only registered one parameter. With this in mind, let's go up a routine and see how data is being passed in:

There are two pushes before the call: the expected kernel32_handle but also API string value. This changes the meaning completely and finally lets the code make sense.
Oh, and Hopper decompiled it just fine :)
At this point we've been able to answer one of our initial questions:
- Why does the initial loader contain so few strings?
Finding the Injected Executable
With the basic framework in place to determine functionality, we can now look for that injected executable that we suspected during dynamic analysis. One aspect that makes it pretty apparent is the large block of tan coloring in the navigation band. This refers to stored data within the file.
The most obvious way to see what's occurring is to go to the first byte of this block of data and xref from that to find where it's being used. In this case, there's one reference to it within the start() routine:

Following that reference we see a pretty large block of code dealing with it. I find it best to represent it as decompiled below, with my variable names already applied:

There is a lot of code here to do something very simple; copy the block of data to another memory space 100 bytes at a time. Then, once done, references a XOR_decode():

Now, note that the code from the decompiled view doesn't actually send four-bytes at a time into XOR_decode(), even though it decodes by DWORDs. Instead, it sends in the current byte position (in increments of 4) and lets XOR_decode() reference the data by its global DWORD location (seen here as decoded_exe). What XOR_decode() does is add that passed position number to 0x85BC, then performs a 4-byte XOR against the current block of data.
Therefore, on the first round, the first four bytes will be XOR'd by 0x85BC. On the second, 0x85C0, then 0x85C4. When complete, you'll have a fully qualified executable (as seen by a debugger):
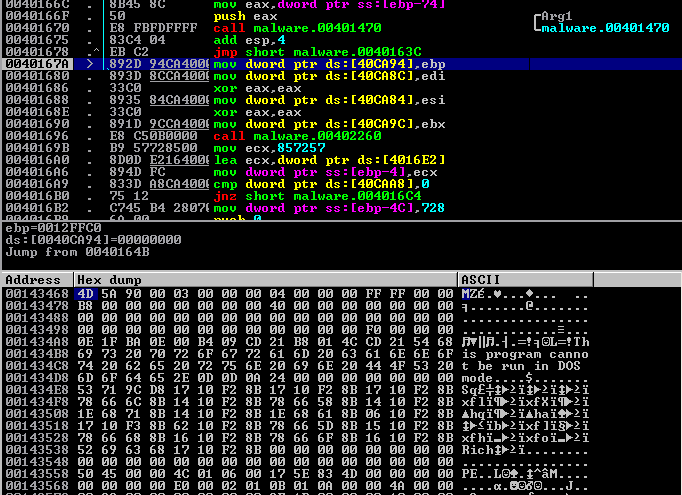
If you dumped it here, or decoded it manually, you'll find it identical to the one that we already extracted in Part 1 using Volatility.
Injected Malware Analysis
With the functionality of the loader complete, we'll close it out and focus on the injected module. As before, this will be a very targeted bag and tag. We have some very specific questions we need answered, but first let's see if there is any groundwork that needs to be completed, such as encoded strings and API resolutions.
Encoded Strings
When we look through the strings of the binary, there are a number of very odd ones that stick out. They're referenced by the code and are likely encoded like the ones in the loader binary.

If I follow them back to see how they're used, some are used in a way that suggests that they're regular strings. For example, this one routine sends them into a subroutine that treats them as HTTP hosts. This suggests that the strings are replaced in-line during execution; the original string is overwritten by the decoded version. Following the string references, I finally see a routine that decodes them, show in decompiled form below:

This routine takes the length of each string and sends it into a routine that I've already named XOR_decode(). XOR_decode() takes the string, the hardcoded value of 15 (0xF) and the length of the string. When viewing the decode routine, it's quite apparent that the 15 (0xF) is a key value and is used in the following loop:

There's a few odd things here. It looks like a basic FOR loop; ESI in incremented after each loop and compared against the string length to break out. I see a byte-by-byte XOR decoding, but there's a small twist. The ECX register is increased in every loop but, once it reaches 3, it resets to 0.
The passed key (0xF) is placed into DL (EDX), then added to by CL (ECX). The resulting value is XOR'd against the respective byte. This literally just makes a five-byte XOR key of 0x0F101112.
After finding the code references to XOR_decode(), we have another problem. The key value varies in some calls... If there's a lot of calls, and many variations on the key, we may have to write an IDA script to do this. To see how they're called, let's drop the ASM output to a text file and grep it to see what values are pushed into the routine:
> grep -B 5 "call.XOR_decode" injected.asm | grep "h$" | sort
push 0Eh
push 0Eh
push 0Eh
push 0Eh
push 0Eh
push 0Eh
push 0Eh
push 0Eh
push 0Eh
push 0Eh
push 0Eh
push 0Fh
push 0Fh
push 0Fh This is promising. There's roughly 14 total calls and most of them are with the same key (0x0E). There will likely be more calls, as the key could've been placed into a reusable variable. This is totally within the realm to do it manually. To do this, I pulled the relevant strings out and wrote a Python script to do the conversion:
def decode(str, key): pos = 0 result = '' for i in range(0, len(str)): result += chr( ord(str[i]) ^ (pos + key) ) if pos <= 3: pos +=1 else: pos = 0 return result strings = [ {'nsrgandttzcub<p`}', 0xF}, {'\x6A\x7C\x62\x7D\x63\x63\x7F\x7F\x75\x67\x21\x73\x7E\x7F', 0xF}, {'\x6A\x64\x3C\x66\x61\x6A\x63\x7A\x73\x3D\x6C\x7F\x7C', 0xF}, {'\x63\x65\x7D\x73\x7D\x68\x7F\x3F\x71\x7C\x62', 0xF}, {'\x7D\x7B\x71\x3E\x79\x60\x60\x73\x7A\x3C\x7E\x67\x60', 0xE}, {'<>"?#<;> #6!!%%', 0xE}, {'\x64\x71\x63\x73\x74\x6E\x7E\x75\x73\x3D\x6C\x7F\x3F\x71\x70', 0xF}, {'\x7B\x62\x22\x3D\x6B\x68\x71\x65\x77\x3D\x7F\x78\x61', 0xF}, {'\x59\x66\x62\x74\x61\x66\x6E\x62\x2A\x7D\x63\x62\x46\x78\x77\x79\x34\x58\x45\x46\x5E\x2F\x51\x7F\x73\x62\x76\x6A\x2A\x46\x7C\x6E\x73\x74\x42\x62\x7A\x63\x22\x20\x35\x41\x75\x65\x65\x61\x7D\x7B\x31\x53\x60\x6E\x7C\x68\x68\x35\x47\x44\x45\x42\x2E\x5C\x7E\x78\x74\x35\x49\x79\x75\x76\x62\x6A\x62\x2A', 0xE}, {'\x6F\x6B\x7F\x73\x77\x20\x6C\x7F\x7C\x29\x69\x6A\x7F\x3E\x62\x7C\x60\x74\x64\x71\x7A\x66\x74\x3F\x62\x66\x7F\x2B\x7A\x77\x7C\x61\x75\x7D\x21\x3C\x34\x65\x62\x77\x7C\x3C\x22\x2A\x65\x67\x61\x79\x7F\x77\x7A\x34\x65\x63\x7E\x63\x60\x7E\x2A\x5A\x5A\x5B\x40\x2A\x62\x6A\x6E\x64\x74\x3C\x6B\x34\x51\x41\x42\x4A\x4E\x44\x50\x29\x4F\x6B\x7F\x73\x77\x35\x7F\x7C\x64\x75\x7D\x34\x51\x75\x70\x5B\x7F\x74\x3F\x7E\x60\x64\x2B\x74\x6A\x7E\x63\x7F\x63\x77\x7C\x21\x75\x69\x77\x35\x67\x64\x65\x62\x34\x34\x74\x7E\x65\x60\x6A\x68\x74\x71\x35\x7A\x60\x75\x73\x7A\x6A\x7D\x74\x29\x76\x6B\x79\x74\x6A\x35\x77\x62\x74\x70\x61\x60\x64\x69\x29\x6A\x6A\x7C\x74\x66\x6B\x7F\x7C\x64\x75\x67\x61\x2B\x7D\x7D\x6F\x6B\x60\x7D\x67\x69\x66\x7E\x2B\x29\x5B\x7F\x74\x70\x66\x6B\x34\x45\x65\x7B\x62\x34\x45\x65\x7B\x62\x21\x75', 0xE}, {'\x6F\x6B\x7F\x73\x77\x20\x6C\x7F\x7C', 0xE}, {'\x63\x66\x73\x63\x7D\x7D\x60\x76\x65\x3C\x6D\x60\x7D', 0xE}, {'\x7B\x7F\x74\x70\x66\x6B\x20\x76\x78\x7C\x6A\x7A\x60\x75\x73\x7A\x6A\x3E\x61\x7A\x7E', 0xE} ] for data, key in strings: decoded = decode(data, key) print "%s => %s" % (data[0:10], decoded)
Upon execution, the results are pretty telling:
> decode_strings.py nsrgandttz => accuratefiles.com j|b}cc¦¦ug => elsoplongt.com jd<fajczs= => et-treska.com ce}s}h¦?q| => lulango.com }{q>y``sz< => sta/knock.php <>"?#<;> # => 212.124.118.147 dqcstn~us= => karaganda.co.cc {b"=khqew= => tr3/xgate.php Yfbtafnb*} => Wireshar;ommView;HTTP Analyz;TracePlus32;Network Analyz;HTTP Snif;Fiddler;
ok⌂sw l⌂|) => adobe.com;geo/productid.php;kernel32;user32;wininet;urlmon;HTTP;pdate.e;APPDATA;Adobe;plugs;AdbUpd.lnk;explorer.exe;http:;downexec;updateme;xdiex;xrebootx;deleteplugin;loadplugin:;Update;Util;Util.e;
ok⌂sw l⌂| => adobe.com
cfsc}}`ve< => microsoft.com{⌂tpfk vx| => update/findupdate.php
Alternatively, this could be done via an IDAPython script. However, there are unique problems to how this sample pushes data into the decoding routine that prevents an easy grab of the encoded text. Sometimes it's an lea of the data into eax, then push eax. Other times it's a push of the direct data offset.
At this point, many examiners would just leave these strings on a list to reference, or put them into the code as comments. However, I prefer to patch the strings in the executable itself. As this is a byte-by-byte encoding routine, we can literally replace the encoded byte with their decoded equivalents within the executable by using a hex editor.
Make a backup copy of the executable then edit the original to find/replace the encoded strings. When done, go to IDA and select File -> Load file -> Reload the input file.
Now, once replaced, the before and after results are pretty awesome:
Before:
After:
As there are no other noticeable forms of obfuscation, we have our executable to a ready state to continue analysis and answer the questions.
One thing to note, as we'll see it during analysis, is a rather interesting lookup function. The large decoded string "adobe.com;geo/productid.php..." is a series of configuration strings in one set. The sample has a basic lookup routine that is passed an integer number. The routine then retrieves that numbered item for usage in whatever function. This is just another form of obfuscation, but also allows for quick portability settings when infecting different regions or targets with the same malware.
Another similar configuration string was found with encoded values intersposed with normal text, resulting in the adobe.com, microsoft.com, and findupdate strings above. This string appeared, in full, as another series of configuration settings used by the malware:
sss:::adobe.com;;;microsoft.com;;;update/findupdate.php;;;6000;;;1;;;0;;;
Dropped / Renamed Files
- What is the encryption routine used for thr1.chm and mmc109.exe?
To determine the structure of thr1.chm, let's first determine where it's written to from the code. By a few simple string searches I found a reference "thr1" and to ".chm". First, the "thr1" appears in the context of:

The structure here, "shedexec:thr1:", and the earlier "shedscr:3:120 <url>" suggest that there's a configuration structure written into the malware with the 'exec' field being thr1. This string is passed into sub_4035F1 which does the following with it:

From these results (shown in decompiler for brevity, and because it won't error out on this :)), we see that sub_4035F1 will take the "shedexec:thr1:" value and parse it for values within colons. This value, "thr1" is then appended to a predefined path of %AppData%\Adobe\shed\ (which we saw in dynamic analysis) and further appended by the extension ".chm", making %AppData%\Adobe\shed\thr1.chm.
We see that unknown data is XOR encoded using the same routine as the strings, and a key of 0xE (14). There's no indication here what that data is, but since we have the file from dynamic analysis we can decode it to receive:
3 http://presentpie.vv.cc/showthread.php?t=332864
Interesting, as these values were also seen two screenshots up in reference to the C2 URL. The meaning of the number is unknown at this point, but we do have the URL that we saw during dynamic analysis AND we know the purpose of the thr1.chm file, to store the C2 beacon address.
- Why does the malware rename mmc109.exe to mmc61753109.exe?
The sample uses CreateDirectoryW, CreateFileW, MoveFileW, and MoveFileExW. Not many samples exclusively use unicode (*W) calls. It's also interesting that both MoveFileW and MoveFileExW are in play, where the latter allows extra control over how files are moved. Typically a sample would just use the basic MoveFileW().
As I access each subroutine that called MoveFileW and MoveFileExW, I spot one that answers our question, shown decompiled below:

There's our "mmc" text, stored as Unicode. I was performing ASCII text searches before, so I missed the reference. To avoid missing this, in your IDA strings display, right click on any string and Setup -> Enable Unicode. However, you'd also need to lower your string length threshold accordingly, which means some strings may still be missed if they're extremely short.
Now, in this routine, I see a folder path being created; following the word_408CB8 back, I see it given the value of the folder %AppData%\Adobe. From there, "\mmc" is tacked on, then two strings are made from that.
Now, in this routine, I see a folder path being created; following the word_408CB8 back, I see it given the value of the folder %AppData%\Adobe. From there, "\mmc" is tacked on, then two strings are made from that.
String one becomes %AppData%\Adobe\mmc%d.exe, where %d is a number retrieved from _rdtsc():
v2 = __rdtsc(); v3 = (16807 * ((HIDWORD(v2) ^ v2) % 127773) - 2836 * ((HIDWORD(v2) ^ v2) / 127773)) % 100000 % 255; v4 = lstrlenW(&FN_exe); wsprintfW(&FN_exe + v4, L"%d", v3);
The second string becomes %AppData%\Adobe\mmc%d.txt where %d is a number retrieved from GetTickCount():
v5 = GetTickCount(); v6 = lstrlenW(&FN_txt); wsprintfW(&FN_txt + v6 , L"%d", v5);
There's where our file names originated.
If, upon execution, the mmc%d.exe already exists, then it is moved to its new mmc%d.txt name.
The rest of this function shows the malware try to download a file from the configured URL, make sure it was saved correctly, then check to see if it has a valid PE Header (begins with "MZ", has a "PE" at the right spot). If it doesn't, then XOR decode it with a key of 0xE and try again. Worked? Great!
Analysis then shows that the .TXT file is a temporary storage location for the executable file. It's likely that this is the allow for updates; moving the current second-stage to a backup file while downloading a new version. Another subroutine (sub_4038AC) shows similar functionality that suggests it is used for trojan updates, however that subroutine creates a folder %AppData%\Adobe\mmc_install.
That should explain most of the file activity we saw during dynamic analysis. Now, onto other things.
Network Beacon Structure
- Why does the malware first make a network connection to Adobe.com? What does that POST value mean?
During runtime we saw a POST request to www.adobe.com/geo/productid.php. This actual URL didn't exist on Adobe's site, and wasn't found in the loader, so where did it come from? And why was it sent?
Since we've already performed string decoding, we've seen these strings pop out at us already. Remember this string?
adobe.com;geo/productid.php;kernel32;user32;wininet;urlmon;HTTP;pdate.e;APPDATA;Adobe;plugs;AdbUpd.lnk;explorer.exe;http:;downexec;updateme;xdiex;xrebootx;deleteplugin;loadplugin:;Update;Util;Util.e;
Following the routines that query this string, I see the request made in the major downloader thread:


This routine takes the server name (cp) and URL (lpString2) and creates a fake HTTP request packet. This packet is then sent and any response is received with recv(). ... And then nothing. It returns and the malware continues on. This HTTP request has no impact on the operation of the malware. Or.. does it?
The payload of the packet is seen above as lpString. When we trace that back in the code, it's the result of a function I've named GetHardDriveInfo(), shown below:

This function has the role of calling certain operating system information and constructing it into a string. My function name was a little short sighted, but fits for now. This routine is basically creating a string of:
_%d_%d_%d
The first %d is the result of a specialized Windows OS checking routine, where a Windows XP system (Major 5, Minor 1) is given the number 6. This is a pretty generically written routine and doesn't need to be shown here.
The second value is the result of GetUserGeoID(), "244". Based on Microsoft's Yet Another Table Of Geo Lookups, this number corresponds to the United States.
The final number is an integer representation of your operating system's partition volume serial number. For example, my serial number is 56F2-F7DB (as obtained by running 'dir'), which is 1458763739 as an integer. When checking with the network traffic from dynamic analysis, everything seems to line up:

While the malware would transmit a beacon to this host, and disregard its response, this action was very critical. It was a first-stage beacon giving your operating system information to the C2 host. In this case, your external IP address, operating system, geographical location, and volume serial number. The last is important for the actor to key in on a unique system out of a set.
Why adobe.com? Obviously that wouldn't work. The only obvious answers are that either there is a localized DNS spoof or if the traffic was being sniffed on the local network.
Conclusions
When we started static analysis, we were given a clear set of questions to answer:- What is the encryption routine used for thr1.chm and mmc109.exe?
- Why does the malware rename mmc109.exe to mmc61753109.exe?
- Why does the malware first make a network connection to Adobe.com? What does that POST value mean?
- Why does the initial loader contain so few strings?
We were able to go in with static analysis and target the answers to each of these. We know the purpose of the loader and how it encoded its strings. We know what encoding routine was used to encode files during dynamic analysis, and what they contained. We know the meaning of the network beacon to adobe.com and the importance of its numbers.
Now what do we do with this newfound knowledge? Write signatures! Preferably YARA rules, written to key on binary data. The challenge is that YARA rules are typically written for data-at-rest, so data found within the injected executable have a very little chance of exposure. So, we'll need to focus on unique aspects of the loader.
While I disdain YARA rules based upon ASCII strings, there are a handful of interesting ones: MlLrqtuhA3x0WmjwNM27 in reference to a registry key and "3etProcAddr" for GetProcessAddress.
The most unique aspect, however, is the data and string decoding routines. The string decoding routine was based upon subtracting the byte position, and the number 0x85BA, from each DWORD. As this is a unique DWORD value, we can key in on that. Turn on the opcode bytes within IDA and examine the hex bytes:
.rdata:0040123A 81 EA BA 85 00 00 sub edx, 85BAh
.rdata:00401476 05 BC 85 00 00 add eax, 85BCh
In action, this set of rules would look similar to:
rule CoreFlood_ldr_strings
{
meta:
author = "Brian Baskin"
date = "13 Feb 14"
comment = "CoreFlood Trojan Loader Strings"
strings:
$RegKey = "MlLrqtuhA3x0WmjwNM27"
$API = "3etProcAddr"
condition:
all of them
}
rule CoreFlood_ldr_decoder
{
meta:
author = "Brian Baskin"
date = "13 Feb 14"
comment = "CoreFlood? Trojan Loader Decoding Keys"
strings:
$Sub_85BA = { 81 EA BA 85 00 00 }
$XOR_85BC= { 05 BC 85 00 00 }
condition:
all of them
}
{
meta:
author = "Brian Baskin"
date = "13 Feb 14"
comment = "CoreFlood? Trojan Loader Decoding Keys"
strings:
$Sub_85BA = { 81 EA BA 85 00 00 }
$XOR_85BC= { 05 BC 85 00 00 }
condition:
all of them
}
At this point, we would want to test this rule across multiple files to ensure that there are no false positives, and that it does hit in on variants. This is best performed using a large-scale internal malware database, that like provided by VXShare.
Looking for hardcoded network traffic will also help us write signatures for Snort or other IDSs. For example, in static analysis, we found the initial HTTP POST traffic sent using a hardcoded user agent of "User-Agent: Opera/10.80 Pesto/2.2.30". This could easily be used to create a signature, after performing a bit of research to determine the commonality of it.
Anything Else?
With the questions answered and rules written, there is a lot of functionality within the trojan that was not analyzed. This was a 1-hour targeted static analysis, so many things were skipped over, or just guessed at. Had this been a proper deep dive (3-4 days) we would have function properly named with all runtime trees documented.
The name here is a bit of an issue. Why is it called CoreFlood? That's what the AV companies called it. However, you don't have to follow their naming conventions for your own malware databases (and many people don't). Based on data presented from the Trojan the two things that pop to mind are 'mmc' and 'shed' as possible names given to the Trojan by its author. The update routine of 'mmc_install' is prominent, but so is the 'shedexec', 'shedscr', and 'delshed' configuration settings. The 'thr1' name was also interesting, but at a lower level; it's possibly a campaign identifier or an actor's initials or signature.
A cursory analysis showed time-based logic in execution. For example, the sample appears to be set to not run before 15 Dec 2010. It will also check the creation time of a local file named Adobe.cer and compare the date against that.
The sample has cursory anti-analysis techniques by comparing the text strings in a list against all of the running processes. This text was composed of:
Wireshar;ommView;HTTP Analyz;TracePlus32;Network Analyz;HTTP Snif;Fiddler;
If this sample was giving issues with dynamic analysis tools, you could easily decode this string, modify it, re-encode it and place it back into the executable.
Why does the sample download a the mmc%d.exe file and check if it's file size is less than 3000?
What does the number "3" mean in front of the URL?
Is there a C2 command structure?
We'll note those questions for later analysis or present them to a client to determine if they're worth spending the time and money to answer.
Very interesting and a ditailed post !
ReplyDeleteHad fun reading it :-)
I also can suggest to look at the string decryption from other side, you can read about in my post ph0sec.github.io - using emulation to help malware help you.
You should remember to use the Y key and fix wrong or incorrectly guessed function prototypes/variable types. If your GetProcAddress() prototype has only one argument (for whatever reason), the decompiler will remove all code which handles the second argument, because it's apparently not used. If you fix the prototype, you'll get correct decompilation.
ReplyDeleteWe take errors in decompilation pretty seriously. If you encounter code which is clearly decompiled incorrectly, please submit a bug report. But in many cases it's an issue of wrong or insufficient input data (GIGO).
- Igor from Hex-Rays
Igor, well met and thank you for your response. "Y" definitely was the fix for this issue, and I wasn't aware of its presence. A coworker who had taken your training relayed how you emphasized that functionality a great deal in the class. This is a testament for people to take training to learn these tricks.
DeleteGreat rread thankyou
ReplyDelete