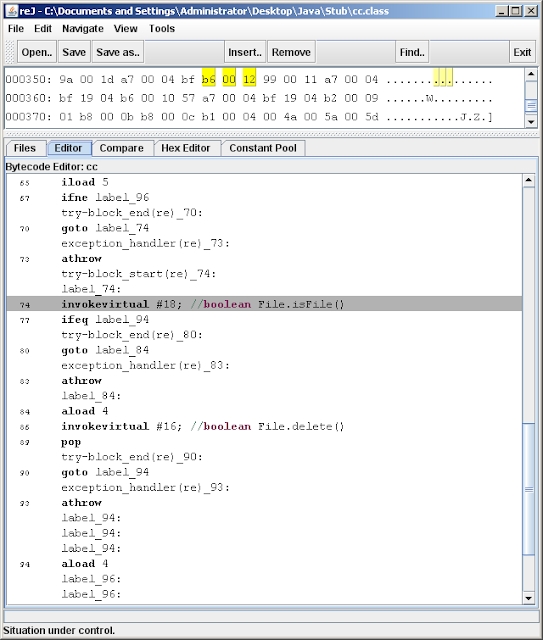
When I first start delving in memory forensics, years ago, we relied upon controlled operating system crashes (to create memory crash dumps) or the old FireWire exploit with a special laptop. Later, software-based tools like regular dd, and win32dd, made the job much easier (and more entertaining as we watched the feuds between mdd and …
Dumping Malware Configuration Data from Memory with Volatility