For a malware analyst, this typically comes about while analyzing code that's beyond the standard trojan, which typically contains no output. Analyzing C2 clients (servers in other contexts) and decoy documents require being able to identify the correct code page for strings so that they appear correctly, can be attributed to a language, and can then be translated.
ASCII is the range of bytes from 0-255, which occupy one byte of storage. UTF-8 extends upon this by using single-byte where possible, but also allowing variable-length bytes that are mathematically calculated to determine the correct byte to use. If you see a string of text that looks like ASCII, but then randomly contains unknown characters, it is likely UTF-8, such as:
C:\users\brian\樿鱼\malware.pdb
Code pages, UTF-16, and even UTF-32, provide additional challenges by providing little context to the data involved. However, I hope that by this point in 2013 we don't need to continually harp on what Unicode is...
For most analysts, their exposure to Unicode is being confronted with unknown text, and then trying to figure out how to get it back into its original language. This text, when illegible, is known as mojibake, a Japanese term for "writing that changes". The data is correct, and it does mean something to someone, but the wrong encoding is being applied. This results in text that looks, well... wrong.
Most analysts have gotten into the habit of searching for unknown characters then guessing which code page or encoding to apply until they produce something that looks legible. This does eventually work, but is a clumsy science. We all have our favorites to try: GB2312, Big5, Cyrillic, 8859-2, etc. But, let's just keep this short and sweet and show you a tool that your peers likely already know about but forgot to show you.
Many times unknown data is found directly in the middle of known text, such as:
C:\users\brian\樿鱼\malware.pdb
That small section of unknown data in the middle is mojibake. The problem you'll find is that if this string of text is stored within a binary file, such as an executable, using a tool like 'strings' will miss it. 'strings' will instead return two strings: "C:\users\brian\" and "malware.pdb", completely missing the folder name that's UTF-8 Chinese.
My preferred method for dealing with these is to simply paste the string into Notepad++. It can natively translate to UTF-8 or various code pages on the fly. Just make sure that you're in ANSI mode when you paste it in.
For graphical applications it's a bit more difficult. Take, for instance, these series of texts from a malware C2 client:
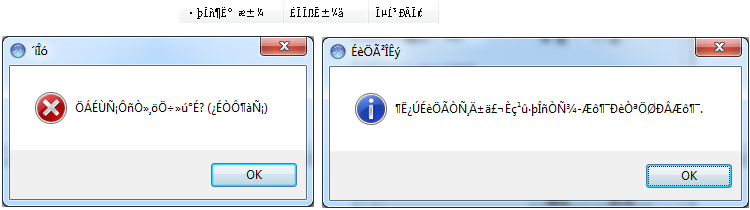
This is mojibake. The standard way that most people get around this issue is to identify the code page from the application, usually by using an application like ExifTool, setting their system to use that language pack as the primary, then rebooting and running the application again. This works, but is cumbersome. Others take VM snapshots of their analysis system in various languages, then just revert to the appropriate language to extract the language strings as needed.
The problem deepens when an application has a mixture of correct strings alongside mojibake strings, such as this program does:

The proper strings are the result of the program containing a String/Dialog resource with appropriate language settings applied. This program, viewed with Cerbero's PEInsider, showed Menus and Dialogs with proper settings applied (2052 - Chinese Simplified):

However, for its string table, the application feature virtually no entries at all. Just a string of "A" and "B".

This provides part of the picture, but doesn't encompass all of the strings we may run across, especially for those created dynamically at runtime.
The preferred way is to use a little-known, but also widely-known, Microsoft tool named AppLocale. AppLocale will run an application in a specific, chosen code page and provide native translation. All that is required is for you to have the appropriate language pack installed, without having to make it the OS's primary language.
However, there are multiple issues with AppLocale. It's a GUI loader that displays the supported languages in their native written format, as shown below, making it impossible to know which is which unless you already know the language.

Good luck with that. Especially when you jump between eight languages in a given week.
AppLocale does allow for command line execution, but requires you to know a specific four-digit code page number. A number that's based on Microsoft's Locale ID that's relatively unknown to outsiders. For instance, with Simplified Chinese, they use Locale ID 0804 instead of the universally known 2052.
To simplify the process, I threw together a quick script over the weekend that provided the full selection of Locale IDs, from which one is selected. It then creates a new option on the right-click context menu for executable files. That's it, nothing major.
The effect is instantaneous though. Edit the script and uncomment the language of your choice, then run the script as an account with administrative access. From there, you can simply right click on any executable and select "Execute with AppLocale". The applications should then show up in their native language without any reboots, like our text below from the earlier C2 client:

Note: If instead of the program running, AppLocale gives you a setup window, then you likely do not have that specified language pack installed.
Software:
Microsoft AppLocale: http://www.microsoft.com/en-us/download/details.aspx?id=13209
RightClick_AppLocale: https://github.com/Rurik/RightClick_AppLocale/blob/master/RCAppLocale.py
Further Fun Reading:
Do You want Coffee with That Mojibake: http://iphone.sys-con.com/node/44480
Unicode Search of Dirty Data, Or: How I Learned to Stop Worrying and Love Unicode Technical Standard #18 Slide Deck (PDF) | White Paper
Russian Post Office fixes mojibake on the fly: http://en.wikipedia.org/wiki/File:Letter_to_Russia_with_krokozyabry.jpg
{kind=link}
Just a thought, but would having the proper windows language packs installed help in this case? assuming the application was compiled properly to have a strings table I guess..or some other resource with the language encoding present?
ReplyDeleteIf the application has a proper string table in its resources, those particular strings will display correctly. I cropped it out of the view on the images here, but this program did have proper Chinese strings for pull-down menu and certain dialogs alongside mojibaked strings for in-line text. The resources were set correctly (language 2052 - Chinese Simplified). I've just gone back and updated the post to better reflect this.
DeleteI've found that even with a comprehensive string table, many applications have a substantial amount of strings that are just printed in-line, or are dynamically constructed with wsprintf().